
题目大意
给定N个单词,求满足下列条件的前缀集合S:
- 集合中任意前缀对应的单词数量小于等于5
- 对于集合中任意前缀
p,p的扩展前缀不属于该集合
对于第二个条件,举个例子来说:
假设ab对应了5个单词,abc对应了3个单词,abd对应了2个单词。
因为ab对应的单词数量少于等于5,所以ab属于集合S。虽然abc和abd对应的单词数量均小于等于5,但由于其为ab的扩展,所以不属于S。
解题思路
由于本题需要询问多个单词的公共前缀,很显然的是一道Trie树的题目,关于Trie树的讲解,可以点击这里学习。
首先我们将所有的单词建立成一颗Trie树,举个例子:
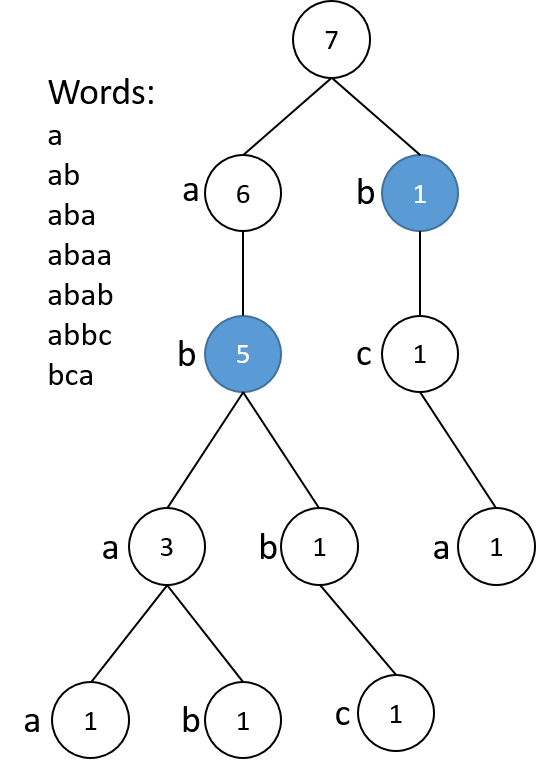
对于树上任意一个节点,表示从根到节点路径构成的前缀,其数字表示该前缀对应的单词数量。
题目中描述的两个条件很容易在该Trie树中判定:
- 当节点数字小于等于5时,则表示该前缀是一个合法解
- 当节点为合法解时,以它为根的子树上其他节点都不再计入合法解
在上图中,蓝色节点表示最后属于集合S的前缀。
由此我们可以得到一个简单的算法:
- 对构建好的Trie树进行遍历
- 若当前节点计数小于等于5,返回1
- 若当前结点计数大于5,递归对所有子树进行遍历,并返回统计和
写成伪代码为:
Traversal(root)
If (root.cnt <= 5)
Return 1
End If
total = 0
For i = 'a' .. 'z'
If root.chd[i] is not empty
total = total + Traversal(root.chd[i])
ENd If
End For
Return total
到此,本题也就顺利的解决了。
如果a的子树有ca前缀,b的也有,是不是应该存在ca前缀,但是这个树却得不到